Typography
Leibniz is a great inventor and user of special symbols. It causes many issues of compatibility between customized LaTeX and other programing languages. The solution to these problems will be a special font based on Unicode encoding. Future editions of Leibniz’s works require a solid encoding basis and a typeface which meets certain requirements. Therefore the development of a special typeface is part of the Philiumm project.
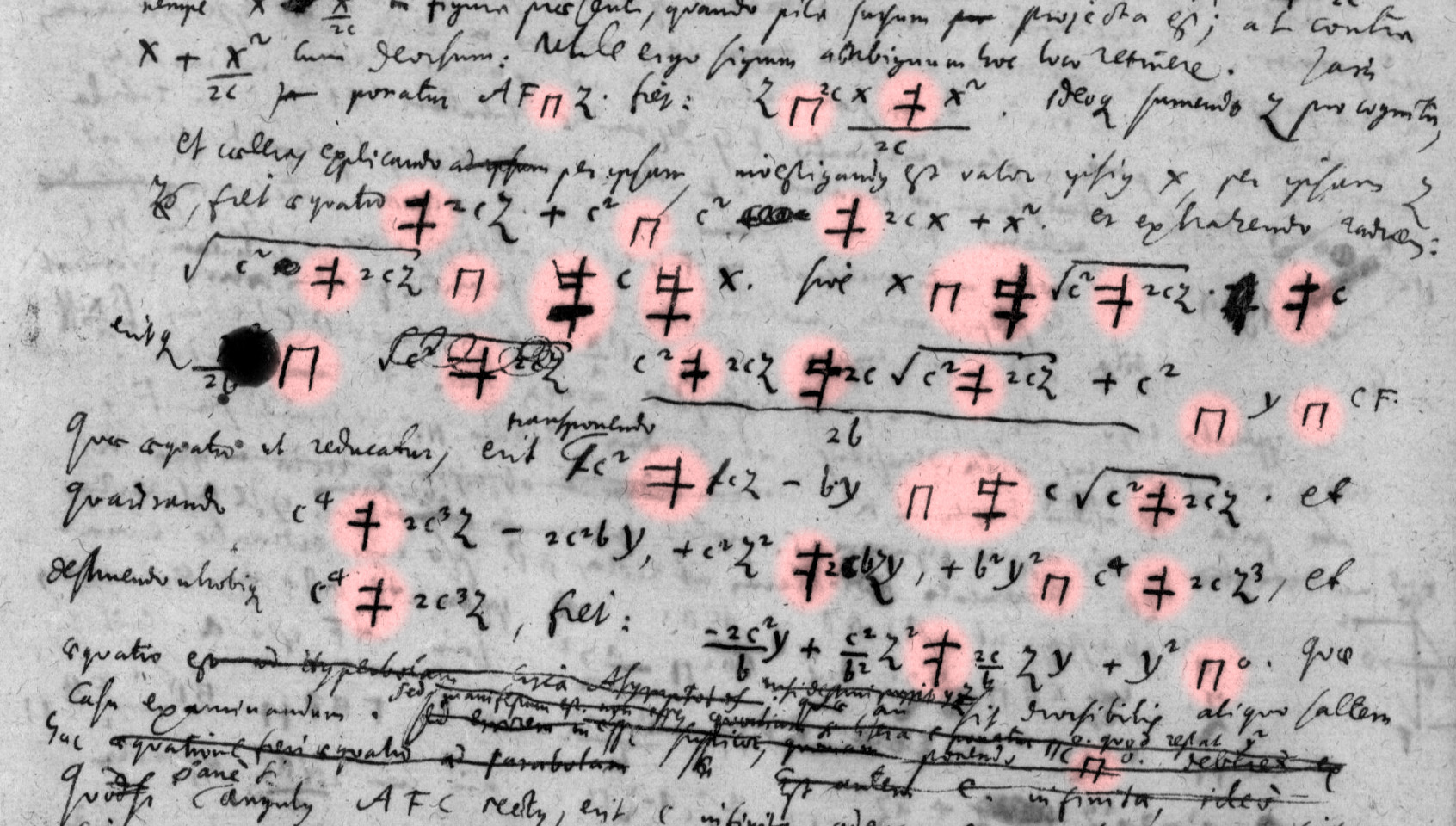
The first requirement is rather a general one: the typographic quality must meet professional design standards to ensure the best possible legibility of long and – in parts – complicated text sources. Even if this may not seem to be overly specific, nevertheless it is undispensable because only a high-quality typypeface is ergonomically functional and ensures the best level of accessibility for all sorts of users. The part of developing a special “Leibnizian” typeface is the contribution of Andreas Stötzner (https://andronfonts.com), who has a background in the development of specialized typefaces for scientific editorial projects.
Within the Philiumm project the typeface development is administered under the name Leibniz Unicode Characters Project (LUCP). The central tool of LUCP cooperation is a central document register, hosting all papers and work files relevant for the encoding and font creation processes.
The second requirement is that the font’s character repertoire has to completely cover all the characters occuring in the relevant text sources, e.g. in Leibniz’s mathematical writings in the first place. A font’s character repertoire is technically based on the Universal Character Set (UCS) as defined by the Unicode Consortium and corresponding ISO working groups. The Unicode standard defines a single hexadecimal code for each character in whatever writing system. The core of the new font will be the quadruplet Latin–Greek–Cyrillic–Hebrew writing systems; all occur in the manuscripts of Leibniz and his correspondents. The font will also contain a large range of mathematical, geometrical and alchemical symbols, as defined in the Unicode standard.

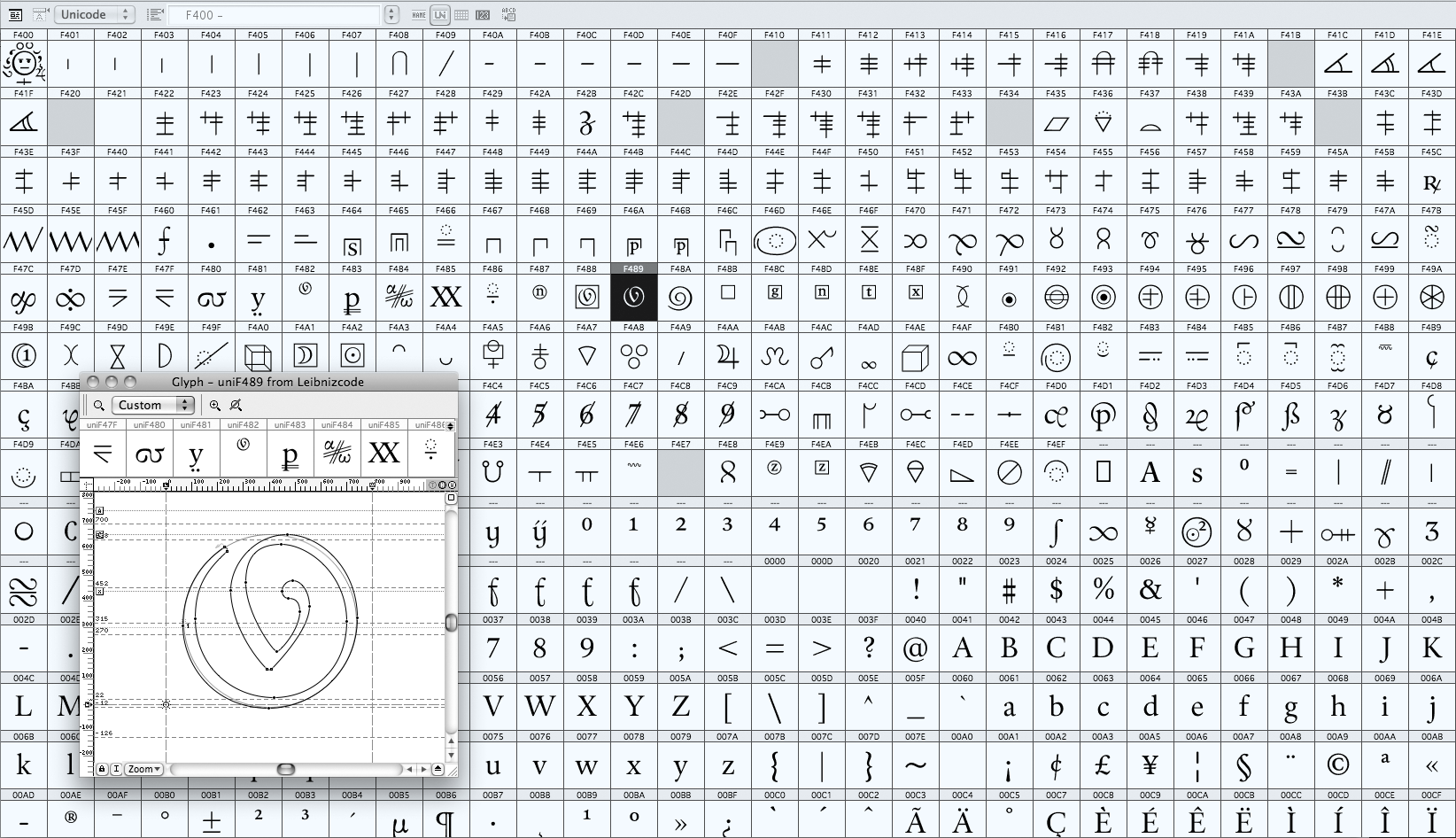
The special challenge lies in all those characters and symbols in the text sources, which have (so far) no official encoding. This is a severe obstacle for a long-term consistent encoding of Leibniz’s texts. All Leibniz scholars are invited to identify and testify further ‘new’ symbols, if editorial work on original sources reveals more special character finds. We have established that, in order to achieve consistency in our text encodings, the so-far not encoded characters need to get official encoding in the UCS. Therefore LUCP forwarded a comprehensive encoding proposal to the Unicode consortium (doc. L-2402n). The encoding procedure started in February 2024 and is currently pending. The process will presumably take up to two years time for successful completion. The acceptance of our character proposal and the official encoding of more than 200 special characters is a key precondition for the realisation of the new typeface.

The Proposal to add historic scientific characters to the UCS (L-2402n) presents on 126 pages 228 new characters for official encoding. This document is the result of a close cooperation with the Leibniz Research Center Hanover, located at the Landesbibliothek Hanover. The proposal had been worked on from September 2022 until February 2024.
The first step was to survey and collect all special characters which are relevant. The volumes of the Leibniz Akademie Ausgabe (LAA) were a good starting point for assembling that list of characters. Once a near-to-complete list had been established, we separated the characters already having an unicode from those which have not. It turned out most of the special characters have no encoding so far.
The proposal for new character encodings presents a thorough documentation of the character’s existence and use, as well as technical and semantic definitions for each single character.
The ‘Leibniz character set’ has been structured into 10 groups, according to their nature and usage:
a) Historical mathematical operators
b) Historical mathematical relations
c) Leibnizian ambiguity signs
d) Geometrical signs
e) Alchemical symbols
f) Miscellaneous scientific signs
g) Superscript characters
h) Letterlike symbols
i) Coss symbols
k) Digit characters
Of these groups, c) and k) form the largest sub-sets. During the work on the proposal, a number of specific semantic problems have been studied and discussed in detail, e.g. the specifics of the several ambiguity sign’s sub-groups or historical interpretation issues with alchemical or cossic symbols. In order to feed the relevant knowledge about all the characters into the encoding process, three additional papers have been submitted together with the proposal (L-2403, L-2404, L-2405). L-2403 is a comprehensive questionaire in which 15 specific encoding issues are adressed.
The design and development of the font progresses simultaneously with the encoding process. Until the special characters proposal is approbated, the standard parts of the font are in the making. An important step in this phase is a decision about the actual character choices, especially for mathematical character groups. The base for the decision process is the Unicode standard and the doc. L-2411.
Before finalization of the font the special characters will get implemented with their new official unicodes. The last stage will be a test phase with a beta-version of the font, in order to detect and fix potential issues. The current LUCP schedule encompasses the creation of a single Regular font. The font will be created in both desktop and webfont file formats. The font will be licenced for free usage, accessible to all interested scholars. For advanced editorial work the addition of a Bold and an Italic font is an option.
