Handwritten Text Recognition (HTR)
We launched an initiative for an open source handwritten text recognition (HTR) model for Leibniz script. It is based on the work of the eScriptorium team, with the help of Thibault Clérice and Alix Chagué.
One of the main goals of the PHILIUMM project is to train this model on the HTR platform eScriptorium. This model would be trained with the ground truth provided by the Berlin team and other transcriptions from the volume 4 of the serie 6 (Reihe VI, Band IV in German) that we plan to add to the new model.
Our work led us to a close collaboration with the team of the Leibniz-Edition Berlin. Harald Siebert and his team already trained a model of automatic transcription on the Transkribus platform of OCR and HTR. The problem of this former model is that we can’t reuse it because Transkribus fail to comply with the FAIR guidelines. We also work very closely with the Leibniz-Archiv in Hanover; we would like to thanks Siegmund Probst, Elisabeth Rinner, Christoph Valentin and Charlotte Wahl for their kind help with the archival collection.
Our participation to Transcriboquest 2024 helped us to understand better the importance of ontology, especially for the sake of interoperability. This notion is one of the foundation of open science.
We also organize a session of the seminar Editing Leibniz, to reflect upon the issues of complex layout of the manuscripts, and also mathematical equations and diagrams drawn; by Leibniz. These particular objects are not recognized by the HTR models. Mathieu Husson, Ségolène Albouy and the EIDA project are using a specific image recognition model for astronomical diagrams.
-
A challenging layout analysis
The segmentation problem arised by Leibniz's draft is interesting. In fact, most of the documents transcribed with HTR technology are intended to be published. It is not the case of most of Leibniz-Archiv archive collection.
Here are the general models of layout analysis that we tried on the Leibniz manuscripts:
Transkribus

We can see that this first model is quite good, even though it's not perfect; we can see that the last lines of both pages are not well segmented.
doc-UFCN

The second model has a worse accuracy than the one of Transkribus. There can be two problems about this bad output: either the ground truth of the general model do not look like the Leibniz manuscripts in terms of layout, or the doc-UFCN model did not "see" enough documents.
Kraken

Even if the reading order of the lines is not right, the output we can see above is the best we have for now. It is the best model to fine-tune —e. g., to train this model specifically on the Leibniz's sources— because it has detected almost all the lines.
-
Finetuning a generic model of automatic transcription
After aligning and preparing the Leibniz ground truth, we trained a first model only with those documents. The accuracy couldn't reach more than 10%. This is due to a lack of data; 142 images of manuscripts are not enough to make a good recognition model. Here we can see that the HTR technology is kinda greedy in terms of data. Now aware of that issue, we took the decision to start from a more general, pre-trained model.
Our first attempt in this direction is the fine-tuning of a model called german_handwriting posted on Zenodo by Stefan Weil (University of Mannheim) in May 2023.
It started from 74.2% of accuracy (epoch 0); after training on the Berlin team ground truth (106 images) and our own ground truth (62 images), it raised up to 90.1% of accuracy (epoch 29), which is a good start.
-
A new step in the training
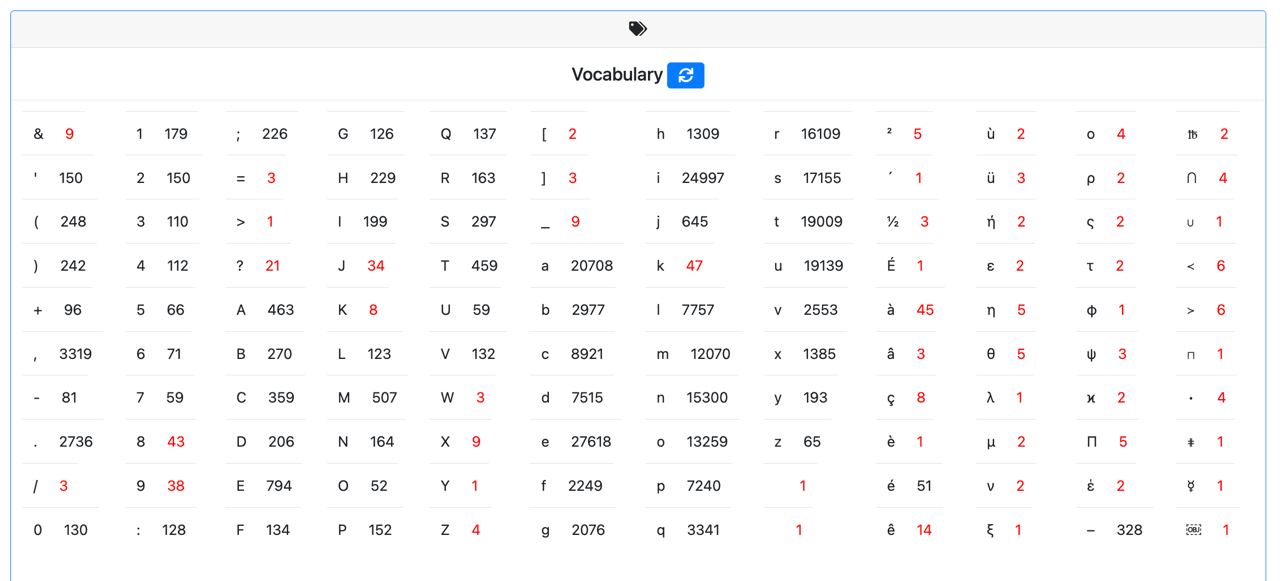
Vincenzo de Risi gave us a new corpus to transcribe. It is also an opportunity to create new data for the model to be more efficient and robust. Here is the number of each character or symbol for the last version of the model. The red numbers indicates that these symbols are under-represented in the ground truth; the model may have not learn them correctly.
This preliminary model allow us to make more ground truth to "feed" again the model with. We transcribed automatically then corrected a new corpus of 72 pages. The aim of this new data input is to try to reach 95% of accuracy.
(Credits: Svetlana Yatsyk)
The list above is only for one of our datasets of training. Since we have currently three corpus to train our models, we have three dictionnaries like this one.
-
Further developments
Another trail that we can follow is to try another general model, for example Manu McFrench (trained with French documents) or CATMuS (latin-based model). Since a significant part of the Leibniz's corpus is written in French, it would be interesting to fine-tune it, then to evaluate the results and the accuracy of the new model. We are creating a fourth dataset base on French sources from Leibniz.